多元copula论文(场景生成)
一、场景样本生成
数据归一化:统一变量尺度。
非参数核密度估计:估计变量边际分布。
多变量相关性建模:使用 Copula 函数描述变量之间的依赖关系。
场景生成:从联合分布中抽样生成初始场景。
场景聚类与削减:通过 EM 聚类和场景削减提取代表性场景。
场景分类与应用:划分场景类型,用于优化建模。
二、KDE(核密度估计)
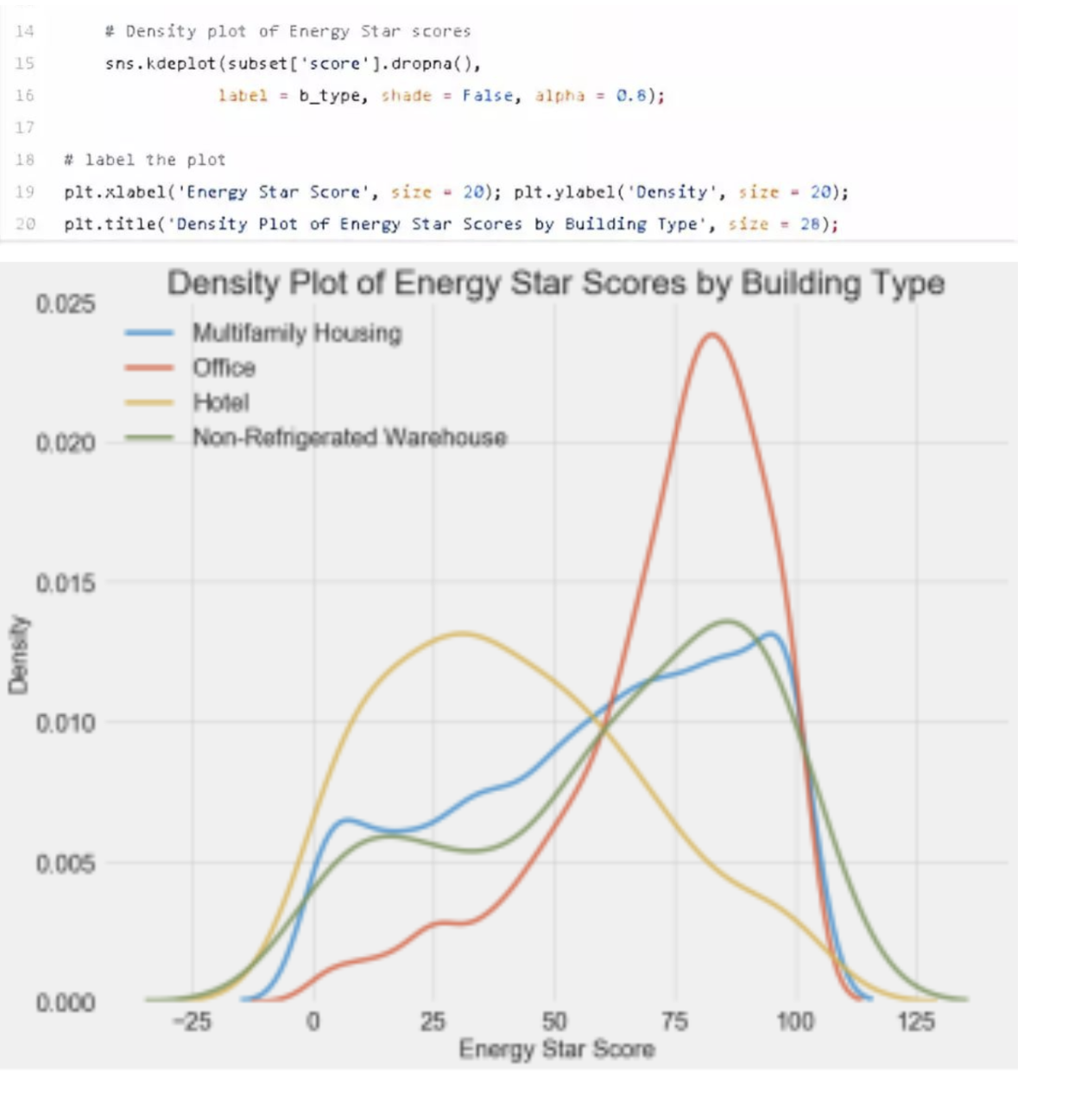
之前energy star数据集也用过kde作图。

1. 核密度估计的定义
核密度估计(KDE)是一种非参数方法,用于从一组样本数据中估计其概率密度函数。
与参数方法(如正态分布拟合)不同,KDE 不需要假设数据服从某种特定的分布。
2. KDE 的公式
对于样本数据 ,其概率密度估计为:
\hat{f}(x) = \frac{1}{n h} \sum_{i=1}^{n} K\left(\frac{x - x_i}{h}\right)
其中:
:样本数量;
:带宽(Bandwidth),控制平滑程度;
:核函数(Kernel Function),描述每个样本点对密度估计的贡献。
3. KDE 的核心参数
核函数 :
核函数用于平滑样本点的影响。常见的核函数包括:
高斯核(Gaussian Kernel):
K(x) = \frac{1}{\sqrt{2\pi}} e^{-\frac{x^2}{2}}均匀核(Uniform Kernel):
K(x) = \begin{cases} \frac{1}{2}, & |x| \leq 1 \\ 0, & \text{otherwise} \end{cases}三角核、Epanechnikov 核 等。
带宽 :
带宽决定了核函数的宽度,直接影响估计的平滑程度:
带宽过小:密度估计过于尖锐,可能导致过拟合;
带宽过大:密度估计过于平滑,可能导致欠拟合。
带宽的选择通常使用经验规则(如 Silverman’s Rule)或交叉验证。
4. KDE 的工作原理
对于每个样本点 ,绘制一个核函数 ,作为该点对密度的贡献。
将所有核函数的值进行叠加,得到总体的概率密度估计。
带宽 控制核函数的扩展范围,从而调整平滑程度。
直观理解:
每个样本点都会形成一个“峰”,这些峰的叠加形成最终的密度曲线(平滑的)。
三、KKT与big-M
1. KKT
KKT 条件(Karush-Kuhn-Tucker)是非线性规划问题的最优性条件。 对于以下非线性规划问题:
\text{minimize: } f(x)
\text{subject to: } g_i(x) \leq 0 \quad (i = 1, 2, ..., m)
h_j(x) = 0 \quad (j = 1, 2, ..., p)
KKT 条件包括:
梯度条件(Lagrangian Optimality):
\nabla f(x^*) + \sum_{i=1}^m \lambda_i \nabla g_i(x^*) + \sum_{j=1}^p \mu_j \nabla h_j(x^*) = 0:目标函数。
:不等式约束。
:等式约束。
:不等式约束的拉格朗日乘子()。
:等式约束的拉格朗日乘子。
可行性条件(Primal Feasibility):
g_i(x^*) \leq 0, \quad h_j(x^*) = 0互补松弛条件(Complementary Slackness):
\lambda_i \cdot g_i(x^*) = 0 \quad (i = 1, 2, ..., m)表示未激活的约束对应的拉格朗日乘子为零。
拉格朗日乘子非负性(Dual Feasibility):
\lambda_i \geq 0 \quad (i = 1, 2, ..., m)
2. big-M
Big-M 方法是一种逻辑约束处理和线性化工具,用于处理混合整数规划中的非线性乘积。
引入一个大常数 ,结合 0-1 变量来控制约束的启用与禁用。
对于非线性关系 ( 是 0-1 变量),Big-M 方法将其线性化为:
z \leq M \cdot \eta, \quad z \leq x, \quad z \geq x - M(1 - \eta), \quad z \geq 0
3. 二者在双层优化中的作用
KKT 条件:
将下层最优解通过 KKT 条件表达为等式和不等式约束,嵌入上层优化模型,构建双层优化的耦合关系。
Big-M 方法:
在线性化非线性关系和处理逻辑约束时发挥作用,确保双层优化问题可以通过线性或混合整数规划工具求解。
总结
KKT 条件:下层最优性条件,帮助将下层问题的解约束在上层模型中。
Big-M 方法:处理非线性和逻辑约束,简化优化问题,提升求解效率。
四、EM聚类
1. 核心思想
与 K-Means 不同,EM(期望最大化)聚类不计算欧几里得距离,而是计算概率。
它通过一个给定的多元高斯概率分布模型,估计每个数据点属于某个聚类的概率。
每个聚类被看作是一个高斯模型。
2. 算法公式
目标是对似然函数 进行最大化:
\theta = \arg \max_\theta \sum_{i=1}^n \sum_{z_i} Q_i(z_i) \log \frac{p(x_i, z_i | \theta)}{Q_i(z_i)}其中:
:数据点 属于聚类 的概率;
:联合分布;
:模型参数(如均值、方差)。
3. 主要步骤
E 步(Expectation Step,期望步)
对于每一个数据点,计算其属于每个聚类的概率,作为权重。
如果一个点很大可能属于一个聚类,就将其概率赋予更高的权重;
如果一个点可能属于多个聚类,则建立一个对聚类的概率分布,形成“软聚类”。
M 步(Maximization Step,最大化步)
根据 E 步计算的权重,重新计算每个聚类的有关参数(如均值、方差)。
五、多元copula用例
场景描述
变量:
光伏功率(PV)
电负荷(Electric Load)
氢负荷(Hydrogen Load)
这些变量之间有复杂的相关性:
光伏功率高时,电负荷可能较低。
电负荷和氢负荷可能正相关。
光伏功率和负荷都受天气和季节影响。
1. 数据处理
收集历史数据:光伏功率、电负荷、氢负荷。
对每个变量进行边际分布拟合:
如光伏功率拟合 Beta 分布,电负荷拟合正态分布。
2. Copula 函数选择
根据变量相关性特点选择合适的 Copula:
Clayton Copula:适合描述低值相关性。
Gumbel Copula:适合描述高值相关性。
高斯 Copula:适合对称相关性。
3. 参数估计
用最大似然估计(MLE)计算 Copula 参数 ,如 。
4. 样本生成
用 Copula 函数生成均匀分布样本。
将均匀分布样本通过边际分布的逆变换生成真实变量值。
总结
Copula 模型将变量的边际分布和相关性分离:
边际分布描述变量的特性。
Copula 函数描述变量之间的相关性。
是模拟能源系统负荷场景的强大工具。
本文章使用limfx的vscode插件快速发布