PL端程序测试
PL端程序已经写好了,数据还是采样率为2M的假数据
下一阶段工作为将PS端工作和这个工程融合到一起
下面为程序测试
基础测试
参数设置
sample_rate:2M
sample_coef:1
sample_mask: ffffffff ffffffff ffffffff ffffffff ffffffff ffffffff
total_sample_num:100
sample_num:50
理论分析
192个通道全部开启,一个采样点有192*2=384字节,2000/384=5(向下取整)
所以1个slice5个sample
有20个slice,2个blob,每个blob有10个slice
实际测试
这是ila运行图,可以看到一个slice有5个sample
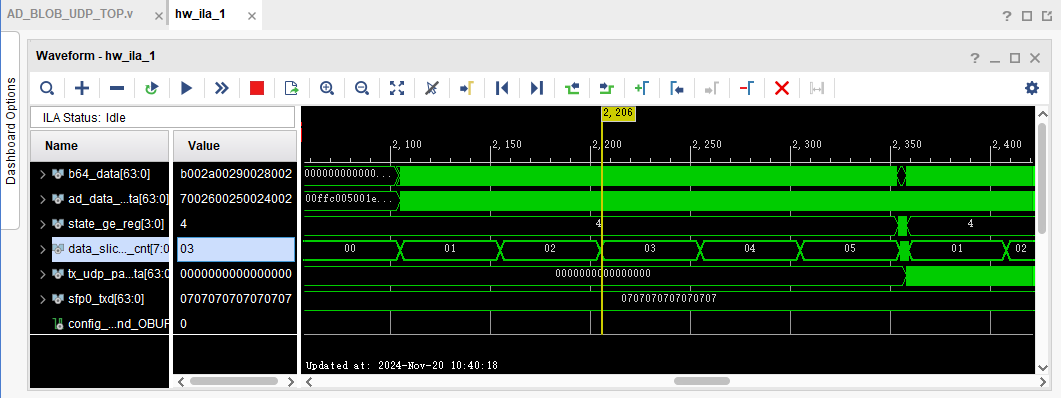
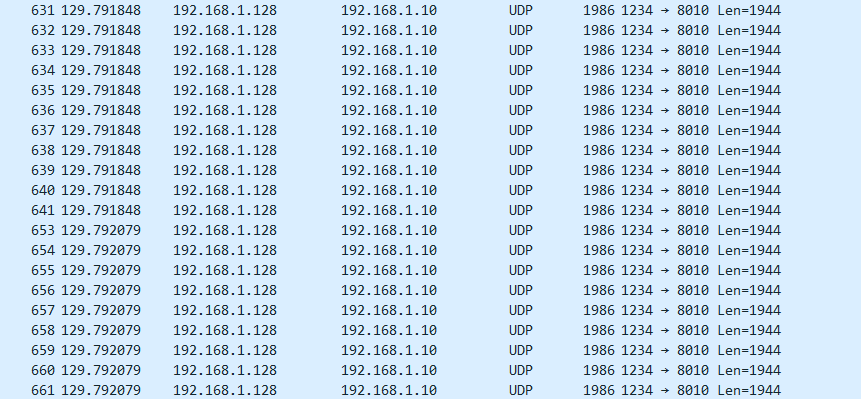
这是wireshark抓包,可以看到抓到了20个UDP包,对应20个slice
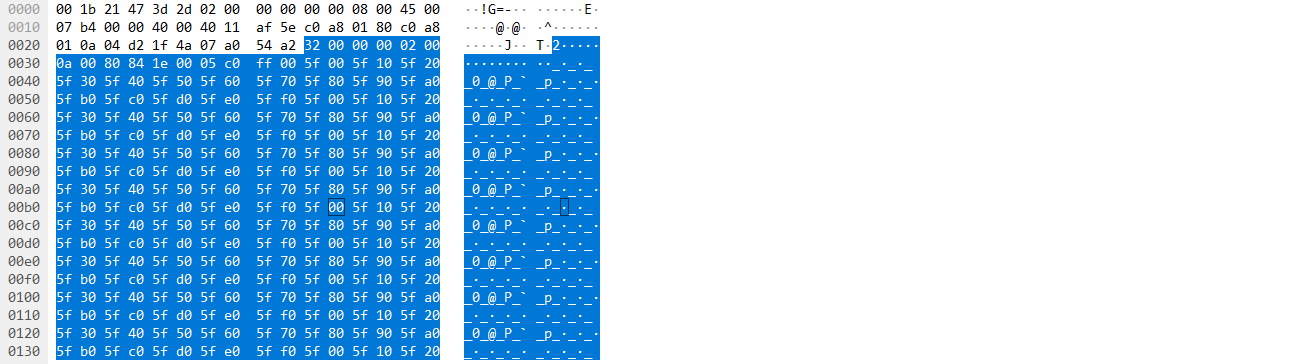
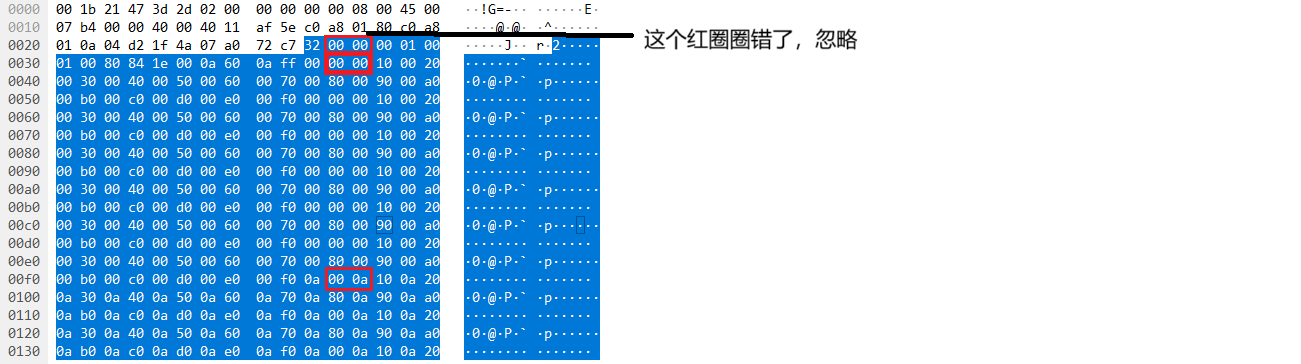
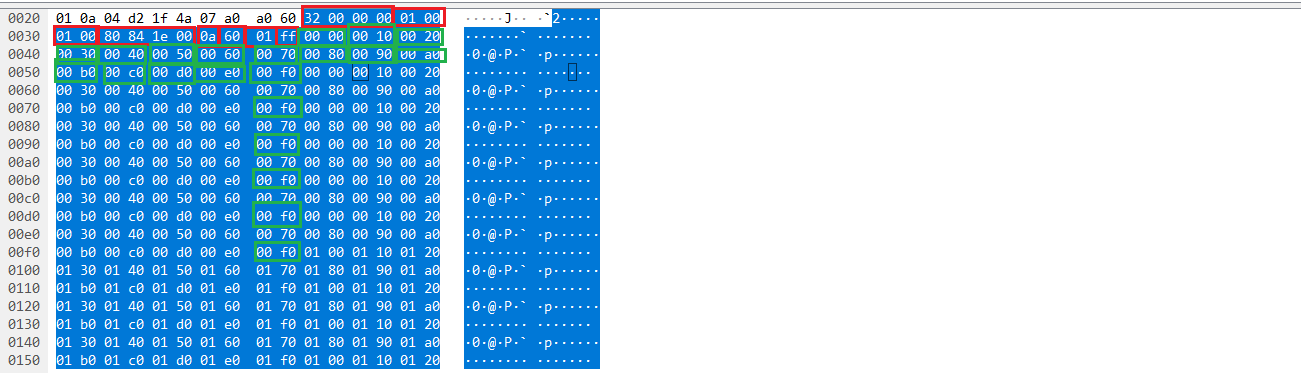
这是第一个slcie的内容,头16个字节(红框内容)为包头,后面为通道内容
通道内容按照ch1-ch192的顺序为
0000 1000 2000 3000
4000 5000 6000 7000
8000 9000 a000 b000
c000 d000 e000 f000
循环排列
每个通道的每次采样值会自增1,所以当读取完ch1到ch192的数据后,可以看到下一个ch1的数据为0001

这是最后一个slice的内容,看一下包头部分为32 00 00 00 02 00 0a 00 80 84 1e 00 05 c0 ff 00
说明blob编号已经增加到2,slice编号增加到10,这是符合理论分析的
n抽1测试
参数设置
sample_rate:2M
sample_coef:10
sample_mask: ffffffff 00000000 ffffffff 00000000 ffffffff 00000000
total_sample_num:1000
sample_num:50
理论分析
开启了96个通道,一个采样点有96*2=192字节,2000/192=10(向下取整)
所以1个slice10个sample
降采样系数为10,即总共采集1000个sample会抽100个sample来传输
所有10个slice,2个blob,每个blob有5个slice
实际测试
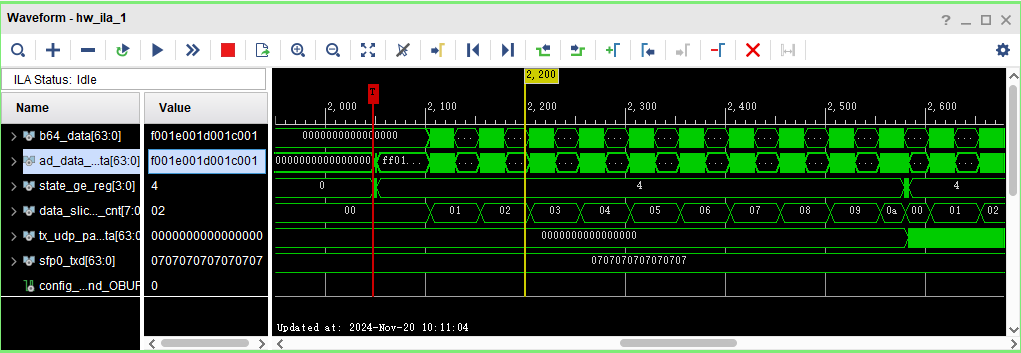
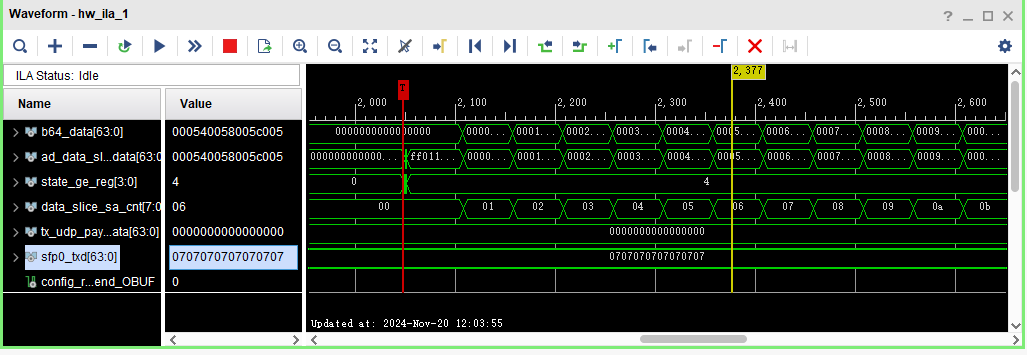
这是ila运行图
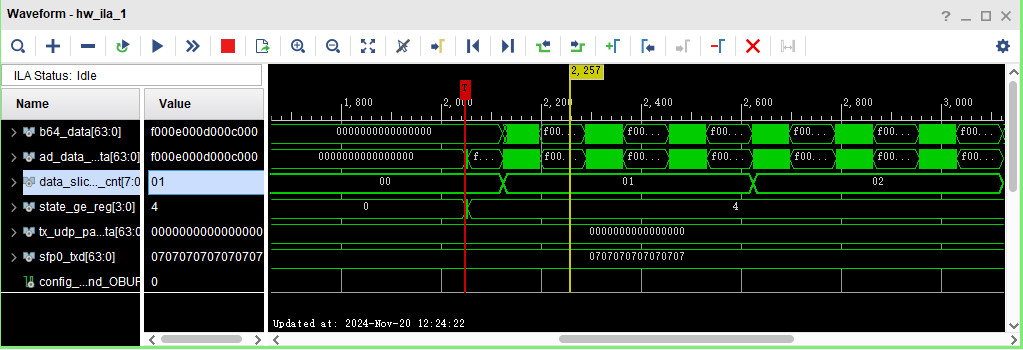
这是wireshark抓包,可以看到抓到了10个UDP包,对应10个slice
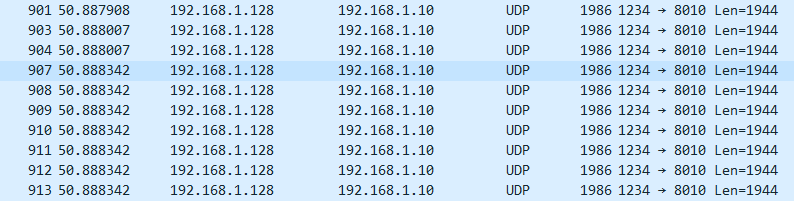
这是第一个slcie的内容
每个通道的每次采样值会自增1,但由于10抽1,所以当读取完ch1到ch192的数据后,可以看到下一个ch1的数据为000a
通道掩码测试
参数设置
sample_rate:2M
sample_coef:1
sample_mask: ffffffff ffffffff ffffffff 00000000 00000000 00000000
total_sample_num:100
sample_num:50
理论分析
开启了96个通道,一个采样点有96*2=192字节,2000/192=10(向下取整)
所以1个slice10个sample
降采样系数为10,即总共采集1000个sample会抽100个sample来传输
所有10个slice,2个blob,每个blob有5个slice
实际测试
这是ila运行图
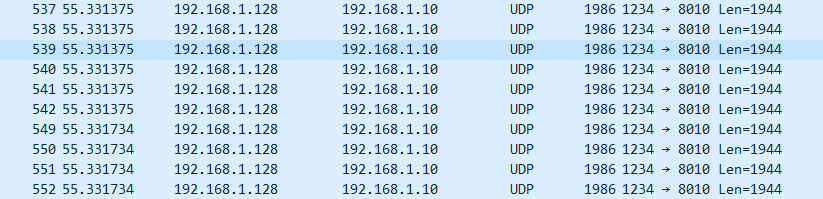
这是wireshark抓包,可以看到抓到了10个UDP包,对应10个slice
这是第一个slcie的内容
通道掩码测试二
参数设置
sample_rate:2M
sample_coef:1
sample_mask: 11111111 11111111 00000000 00000000 00000000 00000000
total_sample_num:1000
sample_num:100
理论分析
开启了16个通道,一个采样点有16*2=32字节,2000/32=62(向下取整)
所以1个slice有62个sample
因为1个blob有100个smaple,所以1个blob有2个slice
其中第一个slice有62个sample,第二个slice有38个sample
一共有10个blob,20个slice
实际测试
这是ila运行图
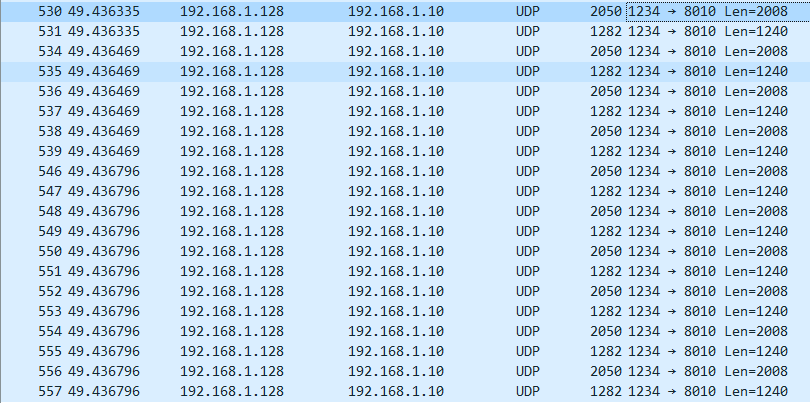
这是wireshark抓包,可以看到抓到了20个UDP包,对应20个slice,而且都是一大一小组成一个blob的
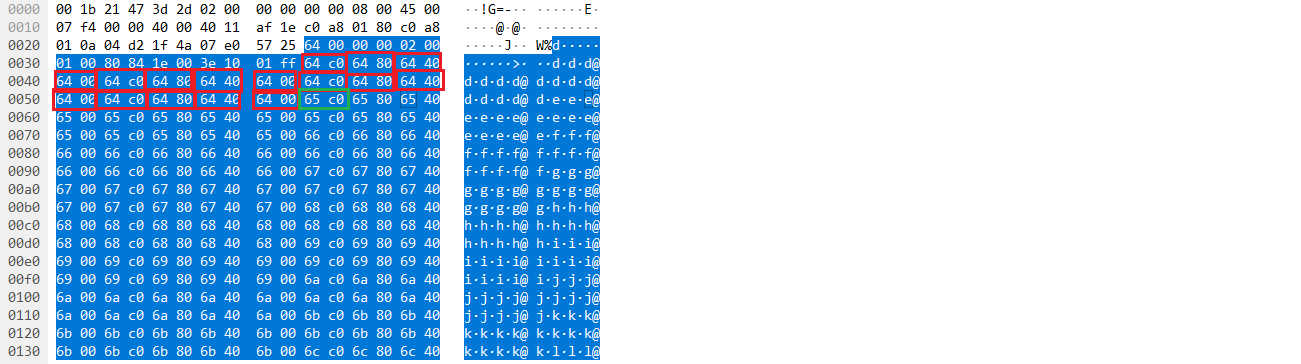
这是第一个slcie的内容,可以看到经过16个ch后内容从c064增加到c065,说明通道掩码设置是正确的
总结
各项参数设置的实际测试均无问题,程序编写无误
本文章使用limfx的vscode插件快速发布