HUTP
简介
HUTP(Hardware UDP Transfer Protocol,硬件UDP高速传输协议)是一个使用UDP实现的网络协议栈,可以将采集到的AD数据组装成UDP包发送,具有高速,低延时,实时传输的优点
参数配置
在开始一次采集之前,上位机可以对采集卡进行参数配置,主要配置以下参数和生成一个job_id:
-
采样率 sample_rate 可调,通常设定为一个整数值,如:20 000 000(20M),2 000 000(2M),500 000(500k),50 000(50k)等
-
采样数 sample_num 表示一个blob会有多少个采样点,另外还有总采样数 total_sample_num 表示一次采集的采样点数,当采够总采样数时采样会停止
-
开启通道掩码 sample_mask 表示192个通道中哪些通道是开启的
-
抽样系数 sample_coef 则是传输中的降采样系数,表示从n个采集的点中抽取一个拿来发送
-
事务编号 job_id 是前三个参数的抽象化表示,只占一个字节,节省空间,在UDP包头中附上job_id,接收端知道job_id就可以判断对应的前三个参数是什么
接收端协议解析
HUTP在FPGA层面实现了一套网络协议栈,主要用于将采集卡采集到的数据进行组装,成为UDP包后通过万兆光纤发送
传输模式有两种:SHOT和STREAM,SHOT模式为开始一次采集,在采集够total_sample_num后就停止了,STREAM模式则是一直采集,知道外界给一个stop的触发信号才会停止
在采集过程中,一次采样中传输的基本单元称为一个blob(采样块),1个blob含有sample_num个采样点,而因为一个blob太大了,一个UDP包是无法装下的,因此要将blob分割为很多个slice(采样片)
一个slice对应着一个实际的UDP包,一个slice里面再包含着多个point(采样点),一个point包含所有开启的通道一个采样周期内采集到的数据
协议中的最小传输单元为一个个UDP包
下图为UDP包payload部分的格式,不包含:以太网帧头帧尾,IP数据报头部,UDP包包头
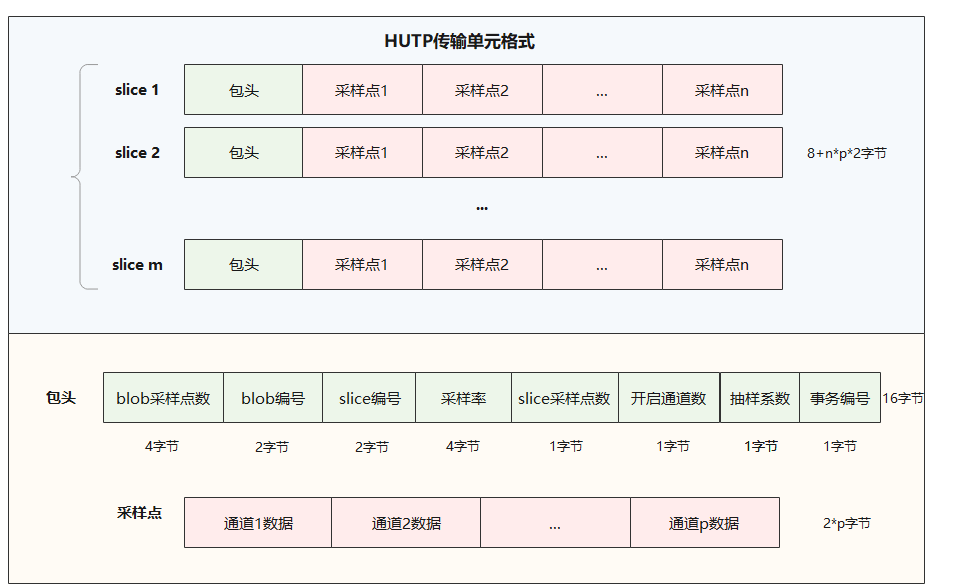
通常设置UDP包payload的最大长度为 2008 2016字节(需开启巨型帧)(普通帧的最大MTU为1500字节,最大UDP payload为1500-20-8=1472字节)
payload部分的头8个字节为采样片包头,后面的所有字节为采样点 (之后可能扩充,包头可能扩展为16字节)
目前设定payload部分的头16个字节为采样片包头,后面的所有字节为采样点
包头信息需要包括:blob编号,slice编号,sample_num,channel_num,job_id等等
包头信息附有job_id,这唯一标识了采样率,采样数,开启通道掩码三个参数,上位机在生成配置参数同时生成了一个job_id,然后配置参数和job_id共同组成了一个job对象,然后会将job对象共享到接收端,接收端在读取包头时获取到job_id就可以知道对应那个job对象,然后知道其参数,根据配置的参数来读取包后面的主体内容
接收端程序只要读取包头就知道如何读取后续payload部分内容,因为假如开启通道数为4,那就8个字节8个字节读后续内容就可以了,开启通道为192,就384个字节384个字节读后面的内容(相当于一次读一个采样点,然后再将采样点的数据按一个个通道分类)
举例分析
开启n个通道,则一个采样点包含n个通道的采样数据,大小为n*2字节 (最多支持192通道)
假设开启4个通道,此时可算得有(2008-8)/(4*2)=250个采样点,每个采样点大小为8个字节,包含4个通道的采集数据,比如为0000 1000 2000 3000这样的形式
值得注意的是,数据包的内容是以大端模式存储的,如8字节包头为
01 00 00 00 fa 00 01 fa,其中前4个字节代表blob编号,5-6字节表示blob采样点数,第7个字节表示slice编号,第8个字节表示slice采样点数,其值分别为00 00 00 01,00 fa,01,fa
也就是说如果是4字节数据,就先取4个字节,然后逆序读取,是2字节数据,就取2个字节,然后逆序读取,1字节就直接读取
现在扩充为16字节包头,不过读取的方式还是以此类推的,01000000 03000000 19000000 05 c0 ff 00 表示blob编号为00 00 00 01,slice编号为00 00 00 03,blob采样点数为00 00 00 19即十进制25,slice采样点数为05,开启通道数为c0,即十进制192,job_id为ff,最后一个字节为空,不表示内容
假设一个4通道采样点数据为00 00 00 10 00 20 00 30,因为每个通道值为2字节数,所以其含义为通道1的值为00 00,通道2的值为10 00,通道3的值为20 00,通道4的值为30 00(这里的值都以16进制表示,最终还需要单位转换)
发送端协议解析
AD数据产生:最多192通道,采样率2MSPS,产生数据为 192 * 2 * 2=784MB/s
以太网数据通路:64bit,最高发送速率为 8B*156.25M=1000MB/s
理论分析以太网传输速率是够满足AD数据产生的最大速率的,能够实现实时传输
实际上通道是可调的,用户可以通过掩码决定192个通道中的任一通道的开启和关闭;并且可以控制整体的采样率(最高2M,往下调整)
由于以太网部分的数据通路位宽为64位,我将AD模块产生的数据转换为进入以太网部分的数据的模块称为b64模块(原意为64b,但出于命名不以数字开头而以字母开头的考虑,命名为b64)
b64模块的设计思路如下所示:
进入AD的信号,统一先转换为有顺序的16bit的b16信号(即代表一个通道的数据,也可以认为是采样数据不可分的最小单位),这个转换的过程是受到配置参数的影响的,如采样率,开启通道掩码, 采样点数。然后再将b16信号组装成b64信号,再送往以太网模块
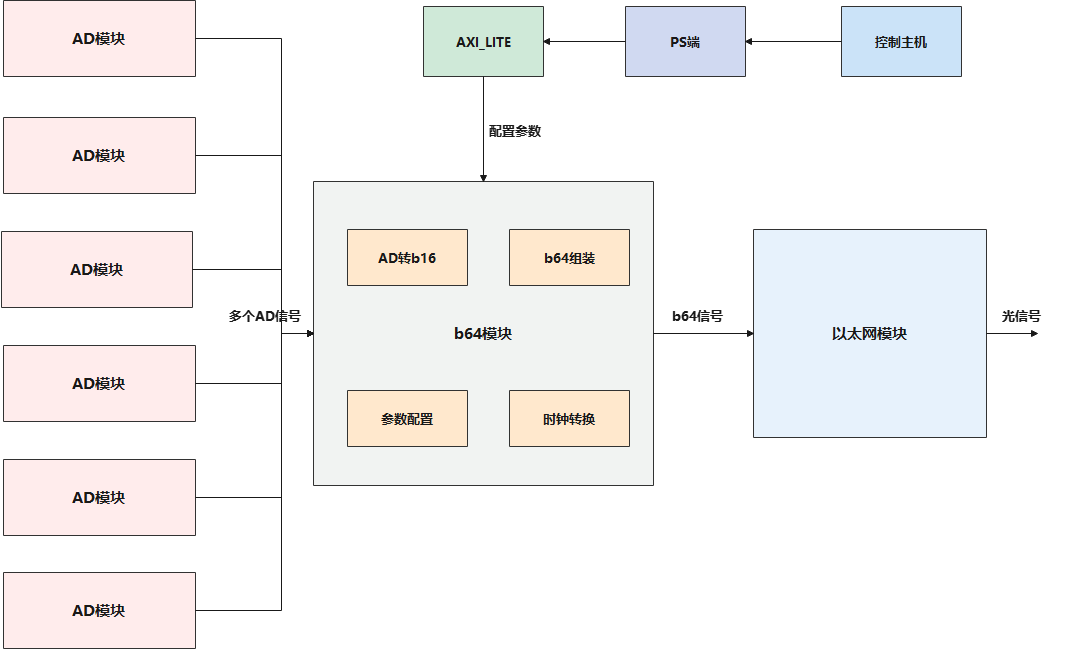
下面是b64模块的实现细节:
降采样
假设AD子卡采集到的数据的采样率统一都是2M,即是每个通道的数据会以2M的频率进行变化(每个数据的持续时间为50ns),而实时传输中的根据抽样参数通过按n:1的形式抽取采集到的数据,即拉长n倍每个通道数据的采样时间实现的,这个过程叫做降采样
可以根据最大采样率(2M)和实际采样率之间的比值得到一个降采样倍数
可以将输入的原始AD数据首先转换为降采样AD数据
生成b16形式数据
然后因为后面将会将降采样数据转换为b16形式(16bit,相当于1个通道的数据),考虑时钟频率和数据位宽的关系,2M的时钟同时产生192个通道的数据,换算成1个通道的数据就需要384M的时钟,因此最大时钟为384Mhz
再通过最大时钟和降采样倍率相比可以得到一个用于生成b16数据的b16时钟clk_b16
实际输入的192通道数据是以32个通道1个模块的形式划分的,所以会从模块1开始按顺序读取到模块6同时读取降采样数据和通道掩码,然后根据通道掩码来决定是否将降采样数据读入到b16数据中(为什么要将数据转换成b16形式呢,因为需要通过通道掩码决定每个通道数据是否要读取并传输)
生成b64形式数据
因为以太网协议栈的数据通路位宽是64位,所以需要将4个b16数据组装起来成为b64数据,在这个过程中还会生成相关的控制信号
首先要生成b64形式的时钟clk_b64,其实就是将clk_b16分频4倍得到的时钟,理论最大值为96Mhz,根据降采样倍率降低
然后将b64数据延时拉长四倍,和clk_b64相匹配
异步FIFO转换
生成的b64数据和信号还要通过一个异步fifo进行转换,才能进入下一个模块
主要有两个目的:
-
跨时钟域转换,从clk_b64转换为clk_100m
-
进行数据缓存,方便后续的插入slice header信息
其实第二个功能才是使用异步fifo的核心原因,如果是单纯的跨时钟域转换其实不一定需要通过fifo实现
关键是如果这边持续产生b64数据,在下一个模块ad_blob_generator中还需要插入header信息(占16字节),那那个header信息就和某个通道的数据产生了冲突(ad_blob_generator组装时读取到了header信息,但忽略了某个b64数据)
为了解决这个问题,就需要增加一个read_b64_ready信号,当下一个模块ad_blob_generator在插入header信息时,就将read_b64_ready设为0,表示这是让fifo不要读b64数据了,等插入完header信息后再将read_b64_ready设为1继续读取
这样就将b64数据缓存到了fifo中,但fifo是不会堆满的,因为输入时钟的最大理论值为96Mhz,而输出时钟为100Mhz,输出时钟是大于输入时钟的,所以因为header产生的缓存数据肯定会读出来,不会越积越多
通道数据掩码对照
首先,一个模块有32通道输入,因此用一个32位掩码来对应每个通道的开关情况
在b64模块中有一段这样的数据(16进制表示),代表1个模块的32通道的512位数据,和b64掩码对应的具体关系如下所示:
3000200010000000 1111
7000600050004000 1111
b000a00090008000 1111
f000e000d000c000 1111
3000200010000000 1111
7000600050004000 1111
b000a00090008000 1111
f000e000d000c000 1111
这段数据发出到接收端后,接受的顺序为ch1,ch2,ch3...ch31,经过大小端转换后如下所示:
0000 1000 2000 3000
4000 5000 6000 7000
8000 9000 a000 b000
c000 d000 e000 f000
0000 1000 2000 3000
4000 5000 6000 7000
8000 9000 a000 b000
c000 d000 e000 f000
根据上面数据制作一个掩码对应表
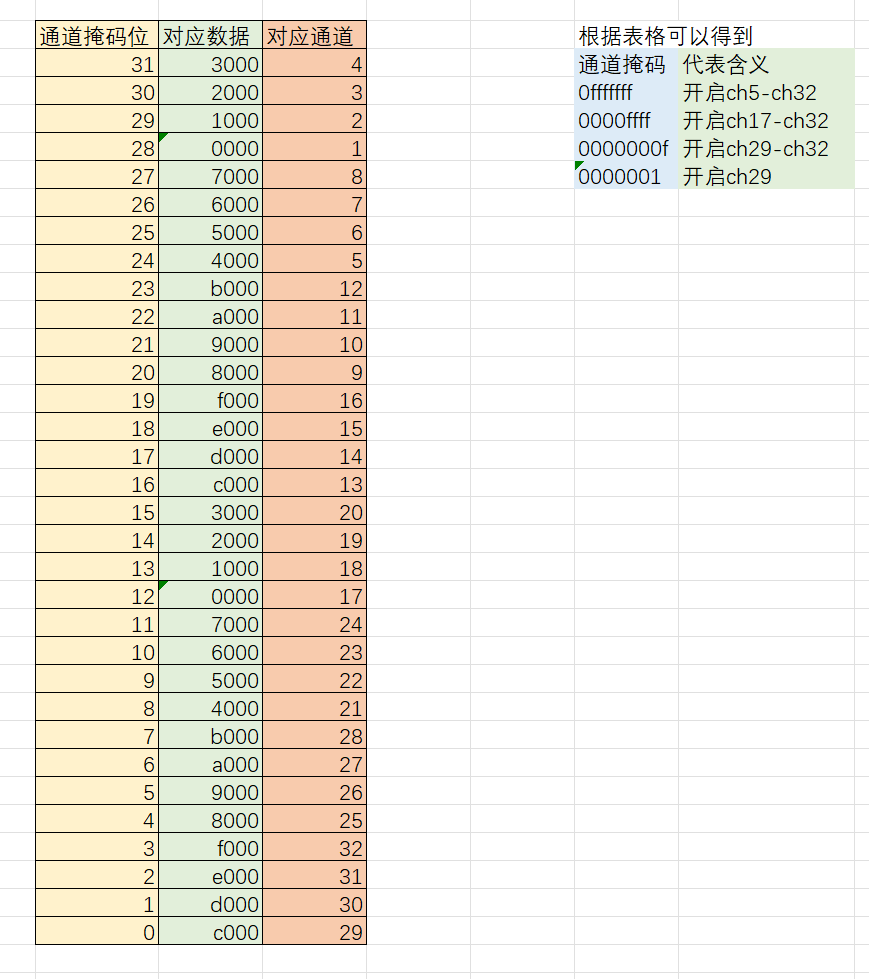
假设用户输入一个通道掩码,其中第n位表示通道n的开启或关闭(这符合通常的逻辑),即第32位表示通道32,第1位表示通道1
这样这个用户掩码和b64掩码之间可以通过一个mask_calculator.c的c程序计算转换,该转换会在PS端完成,然后将转换后的掩码通过axi_lite发向PL部分
#include <stdio.h>
#include <stdlib.h>
int main() {
system("chcp 65001");
unsigned int input;
unsigned int result=0;
printf("请输入一个00000000到ffffffff之间的十六进制数: ");
if (scanf("%x", &input) != 1) {
fprintf(stderr, "输入错误!请确保您输入的是有效的十六进制数。\n");
return EXIT_FAILURE;
}
if (input > 0xFFFFFFFF) {
fprintf(stderr, "输入超出范围!请输入00000000到ffffffff之间的数。\n");
return EXIT_FAILURE;
}
// 转换
result|=(input&0x0000000f)<<28;
result|=(input&0x000000f0)<<20;
result|=(input&0x00000f00)<<12;
result|=(input&0x0000f000)<<4;
result|=(input&0x000f0000)>>4;
result|=(input&0x00f00000)>>12;
result|=(input&0x0f000000)>>20;
result|=(input&0xf0000000)>>28;
printf("转换后的掩码为: %08x\n", result);
return EXIT_SUCCESS;
}
本文章使用limfx的vscode插件快速发布