强化学习案例
1. 强化学习数学原理
【强化学习的数学原理】课程:从零开始到透彻理解(完结)_哔哩哔哩_bilibili
2. 强化学习简单例子
2.1 Maze
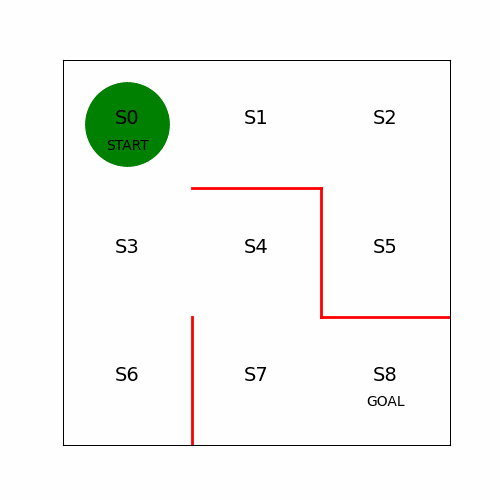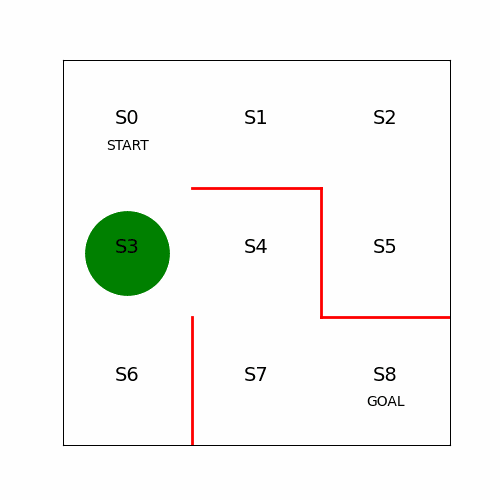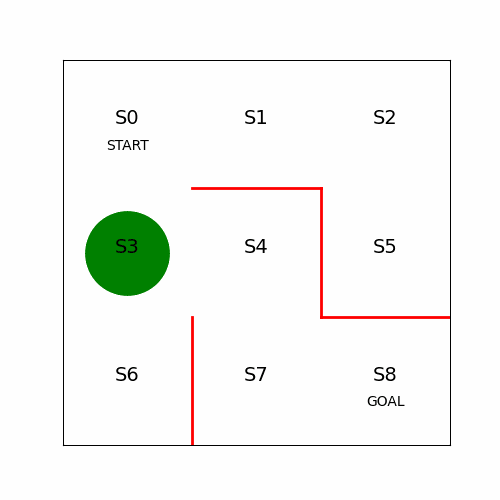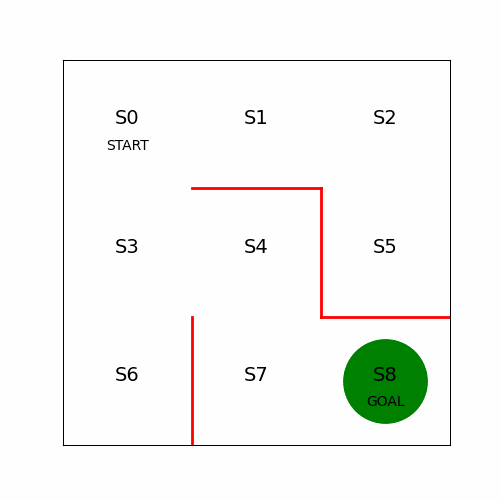
简单的迷宫问题,起始点为,终点为,红线为不可通过。以上帝的俯视视角来看很简单。
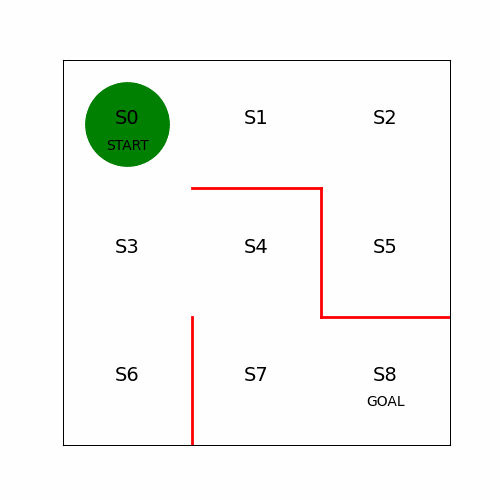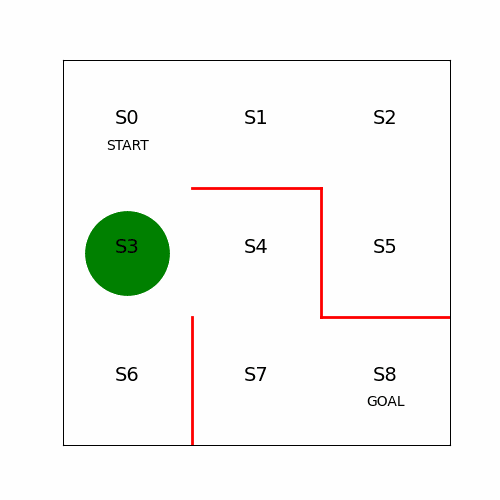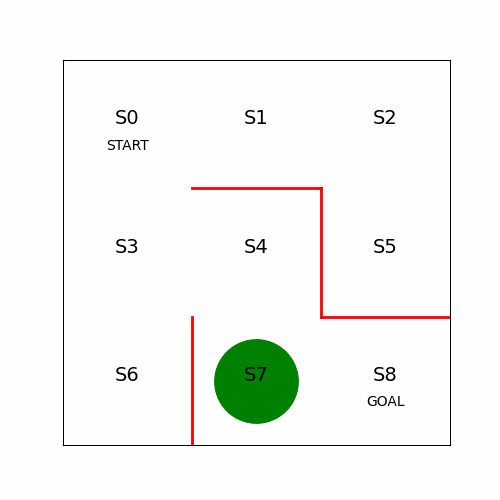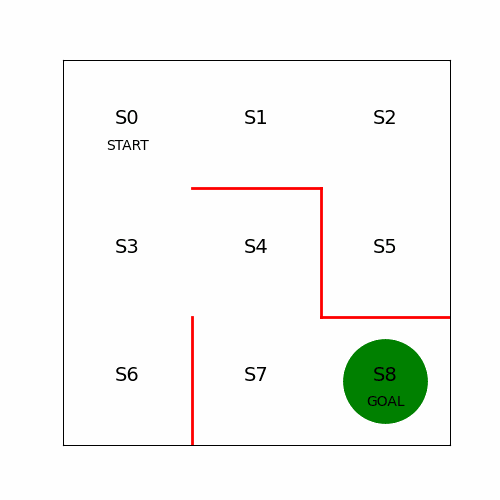
如果关闭上帝视角,置身其中,需要不停地探索,就会发现有非常多的组合。
2.1.1 policy gradient method
策略搜索,直接优化策略,输出的是概率分布
结束要求:策略变化小于时结束学习
收敛速度较慢
2.1.2 SARSA
On-Policy
结束要求:执行100轮试验
2.1.3 Q-Learning
Off-Policy
结束要求:执行100轮试验
动作价值函数更新不同,收敛快于SARSA
2.1.4 complex maze
设计一个更为复杂的迷宫
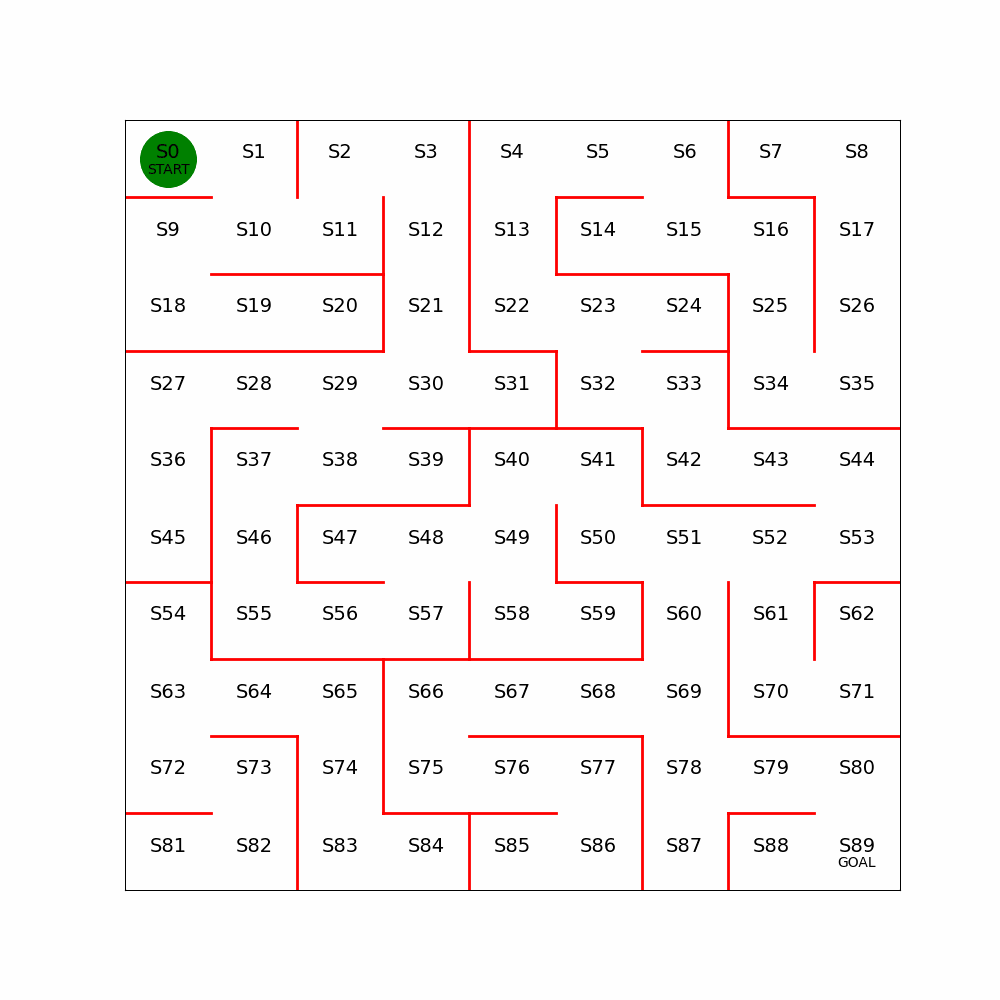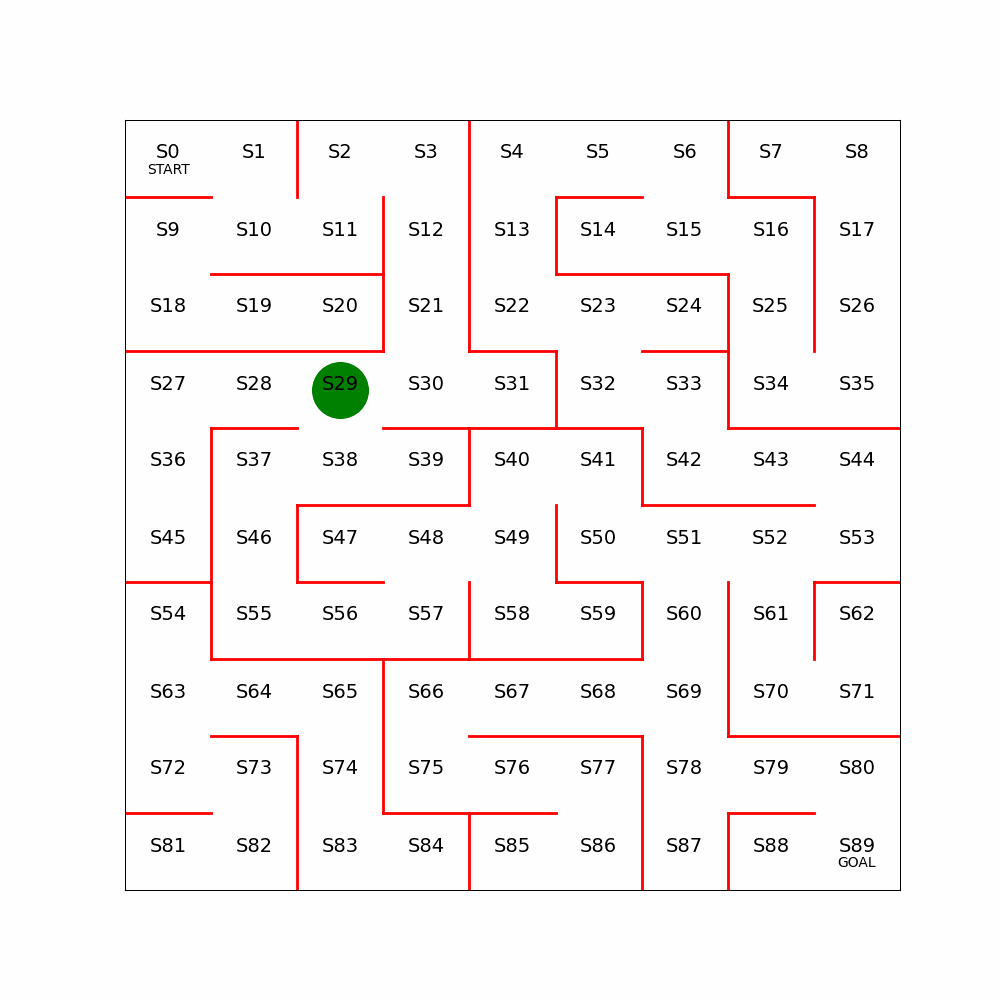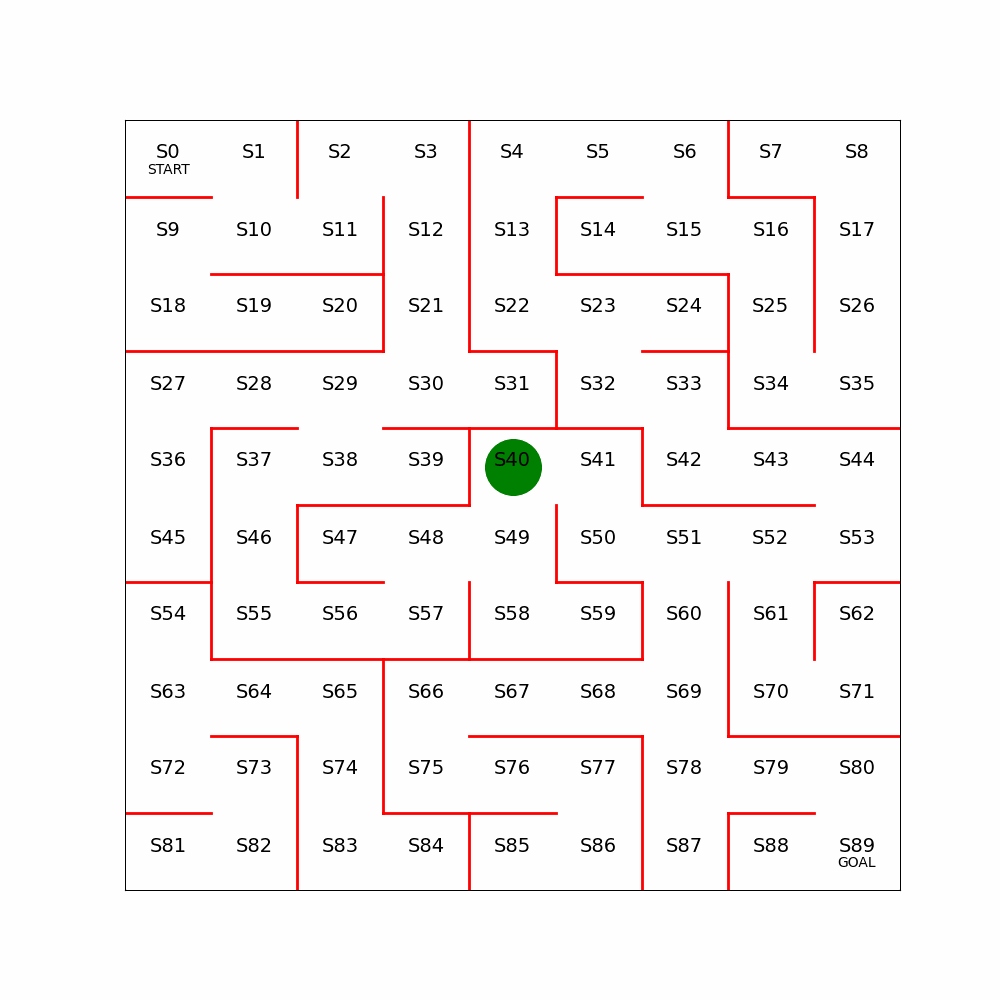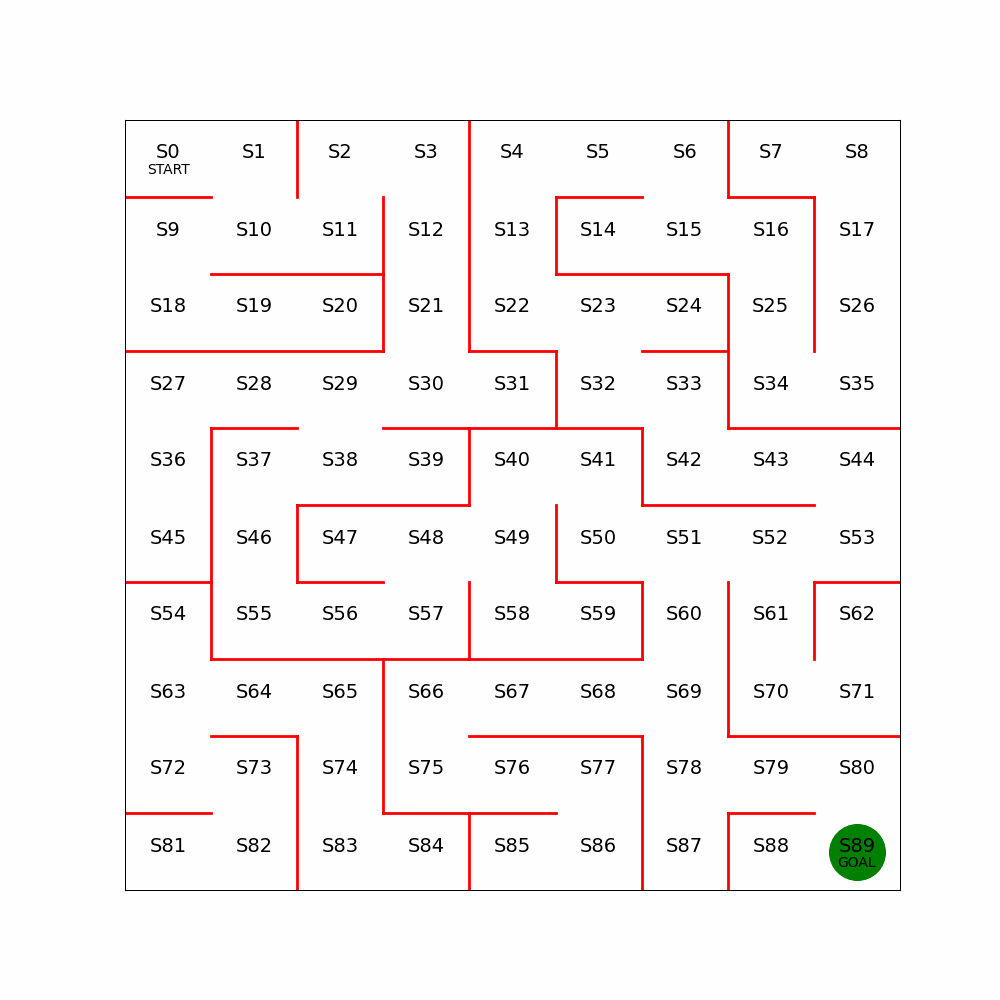
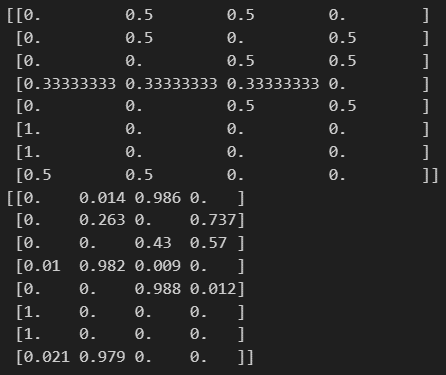
2.2 Cartpole
四个状态变量(小车位置,小车速度,杆的角度,杆的角速度)都是连续值
动作:将小车推向右侧或推向左侧
结束要求:连续十次站立195步及以上或者超过最大试验次数500
2.2.1 Q-Learning
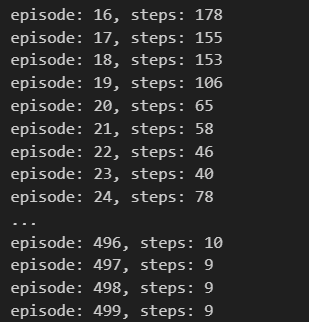
以表格的形式表达Q函数,需要对连续值进行离散化
大约进行240个episode才结束
随着状态变量的类型数量增加,如果每个变量被精细地离散化,表格中的行数会变得很大,解决具有大量状态的任务是不现实的
2.2.2 DQN(Deep Q-Network)
使DQN稳定学习的四个关键思路(experience replay,Fixed Target Q-Network,奖励的裁剪,Huber函数)
如果优先考虑代码实现的简单性,确定动作的主网络和计算误差函数时确定动作价值的目标网络均使用相同的主网络,会出现学习不稳定的情况,超过设定的最大试验次数,仍然没有成功。
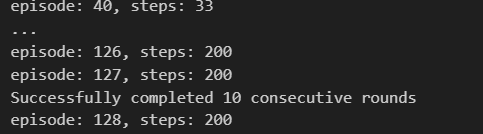
2.2.2 DDQN(Double Deep Q-network)
引入Fixed Target Q-Network,学习更加稳定
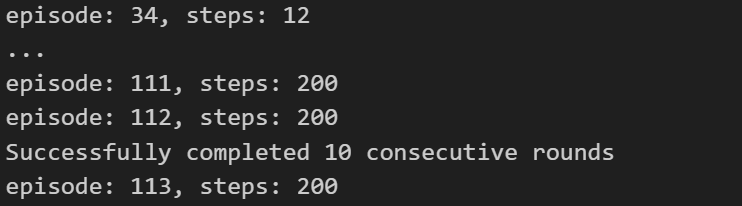
2.2.3 Dueling Network
在动作价值函数的输出层之前增加一层,用于输出状态价值和优势函数,称为Advantage函数。
优点在于无论动作a如何,都可以逐步学习与相关的网络连接参数,因此学习所需的试验轮数比DQN更少。随着动作选择的增加,优势更加明显。
2.2.4 Prioritized Experience Replay
针对学习不到位的状态,对experience replay进行优化,不是随机提取transition,而是根据优先级顺序提取(优先级的排序标准是网络输出与监督信息的差)
相比于随机均匀的从经验回放池中采样的效率更高,可以让模型更快的收敛???
2.2.5 REINFORCE
收敛速度较慢,大约需要1600次试验

2.2.6 A2C
是一种将Advantage和Actor-Critic与分布式强化学习相结合的方法

3. 参考
《边做边学深度强化学习》
本文章使用limfx的vscode插件快速发布